Running local AI with Instruct Lab and Skupper

Welcome to the Ollama Pilot.
Problem to solve

The main goal of this project is to create a secure connection between two sites, enabling the communication between the engineer machine and an Instruct Lab Model. The merlinite-7b-lab-Q4_K_M.gguf model will be used for the chatbot, and it is available in the Instruct Lab. The license of the model is available in the Instruct Labs.
But, why the banner? Well, the engineer needs to know who is better, Lebron or Jordan. The chatbot will be responsible for answering this question. The chatbot will receive the user input and send it to the llama3 model. The response from the merlinite model will be sent back to the user.
Disclaimer
All the models used are available in the Hugging Face model hub. The models are not hosted in this project, they are hosted by Hugging Face. The models are used for educational purposes only.
Why InstructLab
There are many projects rapidly embracing and extending permissively licensed AI models, but they are faced with three main challenges:
- Contribution to LLMs is not possible directly. They show up as forks, which forces consumers to choose a “best-fit” model that isn’t easily extensible. Also, the forks are expensive for model creators to maintain.
- The ability to contribute ideas is limited by a lack of AI/ML expertise. One has to learn how to fork, train, and refine models to see their idea move forward. This is a high barrier to entry.
- There is no direct community governance or best practice around review, curation, and distribution of forked models.
This snippet was extracted from the Instruct Labs repository.
Why Skupper
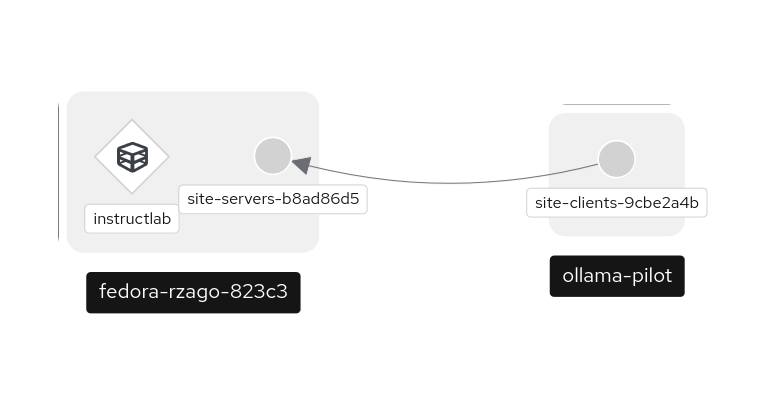
Here the answer is simple, Skupper is a tool that enables secure communication between services in different environments. Skupper will be used to create a secure connection between the two sites, one of the sites has restricted access to the internet. Skupper will enable the communication between the two sites, allowing the Ollama Pilot application to send requests to the llama3 model thru the Instruct Lab chat.
Description
This project has the objective to create a VAN (Virtual Application Network) that enables the connection between two sites:
Site A: A server that hosts the Instruct Lab chat model. This model will be responsible for receiving the user input and sending it to the llama3 model. The response from the llama3 model will be sent back to the user.
Site B: An OpenShift site that exposes the Instruct Lab chat model. This site will be responsible for sending the user input to the Instruct Lab chat model and receiving the response from the Merlinite-7b-lab-Q4_K_M.gguf model.
In order to connect the two sites, we will use Skupper, a tool that enables secure communication between services in different environments. Skupper will be used to create a secure connection between the two sites, allowing the Ollama Pilot application to send requests to the llama3 model and receive the response from the merlinite model.
At the end of the project, you will be able to use your own CHATBOT with protected data.
Architecture
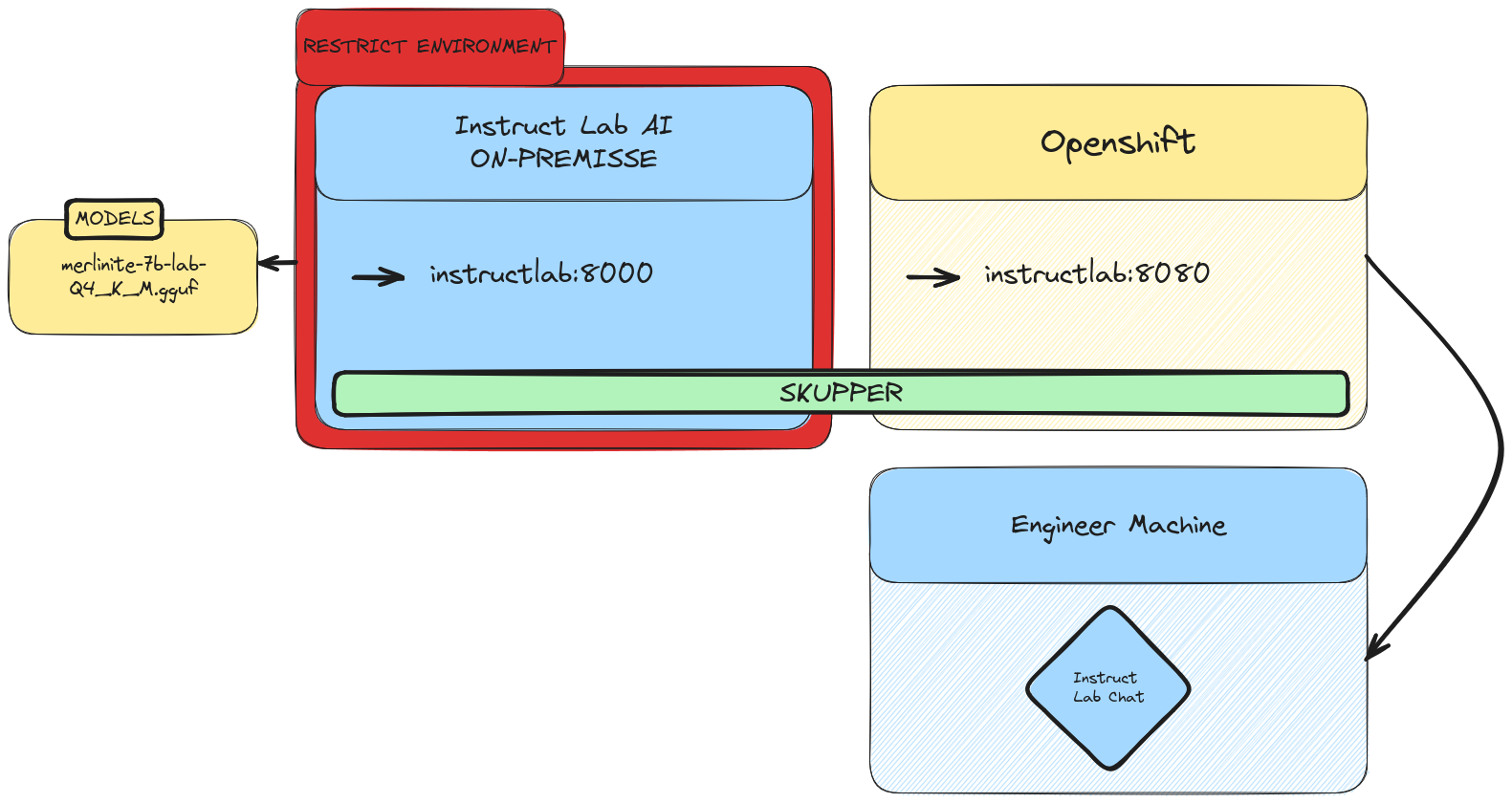
Summary
- AI model deployment with InstructLab
- Private Skupper deployment
- Public Skupper deployment
- Secure communication between the two sites with Skupper
- Chatbot with protected data
1. AI model deployment with InstructLab
The first step is to deploy the InstructLab chat model in the InstructLab site. The InstructLab chat model will be responsible for receiving the user input and sending it to the llama3 model. The response from the llama3 model will be sent back to the user. This is based on the article: Getting started with InstructLab for generative AI model tuning
1
2
3
4
mkdir instructlab && cd instructlab
python3.11 -m venv venv
source venv/bin/activate
pip install 'instructlab[cuda]' -C cmake.args="-DLLAMA_CUDA=on" -C cmake.args="-DLLAMA_NATIVE=off"
IMPORTANT: This installation method will enable your Nvidia GPU to be used by instructlab. If you don’t have an Nvidia GPU, please check other options in: InstructLab 🐶 (ilab)
1
ilab config init
To enable external access to your model, please modify the config.yaml file:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
chat:
context: default
greedy_mode: false
logs_dir: data/chatlogs
max_tokens: null
model: models/merlinite-7b-lab-Q4_K_M.gguf
session: null
vi_mode: false
visible_overflow: true
general:
log_level: INFO
generate:
chunk_word_count: 1000
model: models/merlinite-7b-lab-Q4_K_M.gguf
num_cpus: 10
num_instructions: 100
output_dir: generated
prompt_file: prompt.txt
seed_file: seed_tasks.json
taxonomy_base: origin/main
taxonomy_path: taxonomy
serve:
gpu_layers: -1
host_port: 0.0.0.0:8000 # HERE
max_ctx_size: 4096
model_path: models/merlinite-7b-lab-Q4_K_M.gguf
Now, you can download and start your server:
1
2
3
4
5
6
7
ilab model download
ilab model serve
# The output should be similar to:
INFO 2024-07-30 18:59:01,199 serve.py:51: serve Using model 'models/merlinite-7b-lab-Q4_K_M.gguf' with -1 gpu-layers and 4096 max context size.
INFO 2024-07-30 18:59:01,611 server.py:218: server Starting server process, press CTRL+C to shutdown server...
INFO 2024-07-30 18:59:01,612 server.py:219: server After application startup complete see http://0.0.0.0:8000/docs for API.
2. Private Skupper deployment
The second step is to deploy the private Skupper in Site A. The private Skupper will be responsible for creating a secure connection between the two sites, allowing the Ollama Pilot application to send requests to the llama3 model and receive the response from the merlinite model. Open a new terminal and run the following commands:
Install Skupper
1
2
export SKUPPER_PLATFORM=podman
skupper init --ingress none
Exposing the InstructLab chat model
In order to do this, we will bind the local service that is running the InstructLab chat model to the Skupper service.
1
skupper expose host host.containers.internal --address instructlab --port 8000
Let’s check the status of the Skupper service:
1
2
3
skupper service status
Services exposed through Skupper:
╰─ instructlab:8000 (tcp)
Now, we are almost ready to connect the two sites. The next step is to deploy the public Skupper in Site B and create a connection between the two sites.
3. Public Skupper deployment
The third step is to deploy the public Skupper in Site B. The public Skupper will receive the connection from the private Skupper and create a secure connection between the two sites. Open a new terminal and run the following commands:
- Creating the project and deploying the public Skupper:
1
2
oc new-project ollama-pilot
skupper init --enable-console --enable-flow-collector --console-user admin --console-password admin
- Creating the token to allow the private Skupper to connect to the public Skupper:
1
skupper token create token.yaml
At this point, you should have a token.yaml file with the token to connect the two sites. The next step is to link the two sites. For this, we will need to switch back to the terminal where the private Skupper is running.
4. Secure communication between the two sites with Skupper
The fourth step is to connect the two sites. In the terminal where the private Skupper is running, run the following command:
1
skupper link create token.yaml --name instructlab # Or any other name you want
Let’s check the status of the Skupper link:
1
2
3
4
5
6
7
8
9
skupper link status
Links created from this site:
Link instructlab is connected
Current links from other sites that are connected:
There are no connected links
Before continuing, let’s hop back to the terminal where the public Skupper is running and check the status of the link:
1
2
3
4
5
6
7
8
9
skupper link status
Links created from this site:
There are no links configured or connected
Current links from other sites that are connected:
Incoming link from site b8ad86d5-9680-4fea-9c07-ea7ee394e0bd
5. Chatbot with protected data
Now the last part is to expose the service in the public Skupper and create the Ollama Pilot application.
- Still on the terminal where the public Skupper is running, run the following command to expose the service. With the following command, we will create a Skupper service that matches the service exposed by the private Skupper. This will end up creating a Kubernetes service that will be used by the Ollama Pilot application.
1
skupper service create instructlab 8000
- Exposing the service to the internet:
1
oc expose service instructlab
- Getting the public URL:
1
2
3
oc get route instructlab
NAME HOST/PORT PATH SERVICES PORT TERMINATION WILDCARD
instructlab instructlab-ollama-pilot.apps.your-cluster-url instructlab port8000 None
- The last step is to create the Ollama Pilot application. The Ollama Pilot application will be responsible for sending the user input to the Instruct Lab chat model and receiving the response from the Merlinite-7b-lab-Q4_K_M.gguf model. The Ollama Pilot application will be able to send requests to the Instruct Lab chat model through the secure connection created by Skupper.
You can repeat all the instructions in step 1. AI model deployment with InstructLab to install the Instruct Lab chat model in Site B. The only difference is that you will not run the ilab model serve command because the Instruct Lab chat model is already running in Site A.
The Ollama Pilot application will be responsible for sending the user input to the Instruct Lab chat model and receiving the response from the Merlinite-7b-lab-Q4_K_M.gguf model. The Ollama Pilot application will be able to send requests to the Instruct Lab chat model through the secure connection created by Skupper.
1
2
3
4
5
ilab model chat --endpoint-url http://instructlab-ollama-pilot.apps.your-cluster-url/v1/
╭─────────────────────────────────────────────── system ────────────────────────────────────────────────
│ Welcome to InstructLab Chat w/ MODELS/MERLINITE-7B-LAB-Q4_K_M.GGUF (type /h for help)
╰──────────────────────────────────────────────────────────────────────────────────────────────────────
>>> [S][default]
THE question:
Yes or No question. Don’t fool me. Is LeBron better than Jordan?
Have fun with your new chatbot with protected data! If you don’t agree with the answer, you can always ask again and train your model, but King James is the best!