O Que Acontece Quando Você Conversa com uma IA
Desvendando os modelos de linguagem de grande escala
Quando você digita uma mensagem pro ChatGPT ou pro Claude, o que acontece do outro lado é mais simples do que parece, mas opera numa escala difícil de visualizar.
A essência: um narrador de futebol digital
Imagine a cena: final de Copa do Mundo, Brasil e Argentina, últimos minutos de jogo. O Galvão Bueno está narrando, a bola chega no atacante brasileiro, ele dribla um, dribla dois… e de repente o áudio falha. A transmissão continua, mas a voz do narrador desapareceu.
Agora imagine que você tem uma máquina capaz de analisar tudo que o Galvão disse até aquele momento, o tom, o ritmo, os bordões, o contexto do jogo, e prever qual seria a próxima palavra que ele diria. “Vai que é tua…“, “Haja coração…“, “GOOOOOL…“?
Com essa máquina, você poderia completar a narração palavra por palavra: alimentar o que já foi dito, receber uma previsão da próxima palavra mais provável, adicionar essa palavra à narração, e repetir até completar a transmissão inteira.
É basicamente isso que um LLM faz.
Um modelo de linguagem de grande escala é essencialmente uma função matemática sofisticada que recebe um texto como entrada e produz uma distribuição de probabilidades sobre todas as possíveis próximas palavras (ou, mais precisamente, tokens). É como ter milhares de narradores internos votando em qual seria a próxima palavra mais adequada.
Probabilidades, não certezas
Vale notar: o modelo não “decide” qual palavra vem a seguir. Em vez disso, ele atribui uma probabilidade a cada palavra do seu vocabulário. Por exemplo:
| Próxima Palavra | Probabilidade |
|---|---|
| “hoje” | 32% |
| “agora” | 18% |
| “aqui” | 12% |
| “sempre” | 8% |
| … | … |
O sistema então seleciona uma palavra com base nessas probabilidades. Esse processo de amostragem é controlado por um parâmetro chamado temperatura:
- Temperatura baixa: O modelo age como um narrador contido, tipo Milton Leite: escolhe as palavras mais prováveis e seguras, gerando respostas previsíveis e conservadoras
- Temperatura alta: O modelo vira um Galvão empolgado em final de Copa: aceita palavras menos prováveis e as respostas ficam mais criativas e emocionantes (mas potencialmente menos coerentes)
Isso explica por que você pode fazer a mesma pergunta várias vezes e receber respostas diferentes. Dois narradores nunca descrevem o mesmo lance da mesma forma; o modelo introduz variação através desse processo de amostragem.
O treinamento: absorvendo a internet
Como um modelo aprende a fazer essas previsões? A resposta está no volume enorme de dados de treinamento.
A escala dos dados
Para contextualizar: se você lesse 24 horas por dia, sem pausas, levaria aproximadamente 2.600 anos para consumir a quantidade de texto usada no GPT-3. O GPT-4 utilizou um volume estimado em 10 a 20 vezes maior. Modelos como Llama 3 da Meta foram treinados com mais de 15 trilhões de tokens.
O modelo processa todo esse texto através de um objetivo simples: dado um trecho de texto, prever qual é a próxima palavra. Parece trivial, mas esse objetivo força o modelo a desenvolver uma compreensão profunda da linguagem. O modelo acaba aprendendo:
- Gramática e sintaxe
- Contexto e coerência
- Conhecimento factual
- Raciocínio lógico (até certo ponto)
Parâmetros: os controles do modelo
Um LLM é definido por bilhões (às vezes trilhões) de valores numéricos chamados parâmetros ou pesos. Pense neles como os controles de uma mesa de som com bilhões de controles: cada ajuste altera sutilmente como o modelo se comporta.
O GPT-4 possui estimados 1,7 trilhão de parâmetros. O Llama 3.1 da Meta tem versões de 8B, 70B e 405B parâmetros. O Claude 3 Opus tem cerca de 175 bilhões.
Retropropagação: aprendendo com os erros
Nenhum humano ajusta esses parâmetros manualmente. Eles começam com valores aleatórios (o modelo inicial produz apenas ruído) e são refinados através de um processo chamado retropropagação (backpropagation):
- O modelo recebe um texto de treinamento (menos a última palavra)
- Faz uma previsão sobre qual seria a próxima palavra
- Compara sua previsão com a palavra real
- Um algoritmo ajusta todos os parâmetros para tornar o modelo ligeiramente mais propenso a acertar da próxima vez
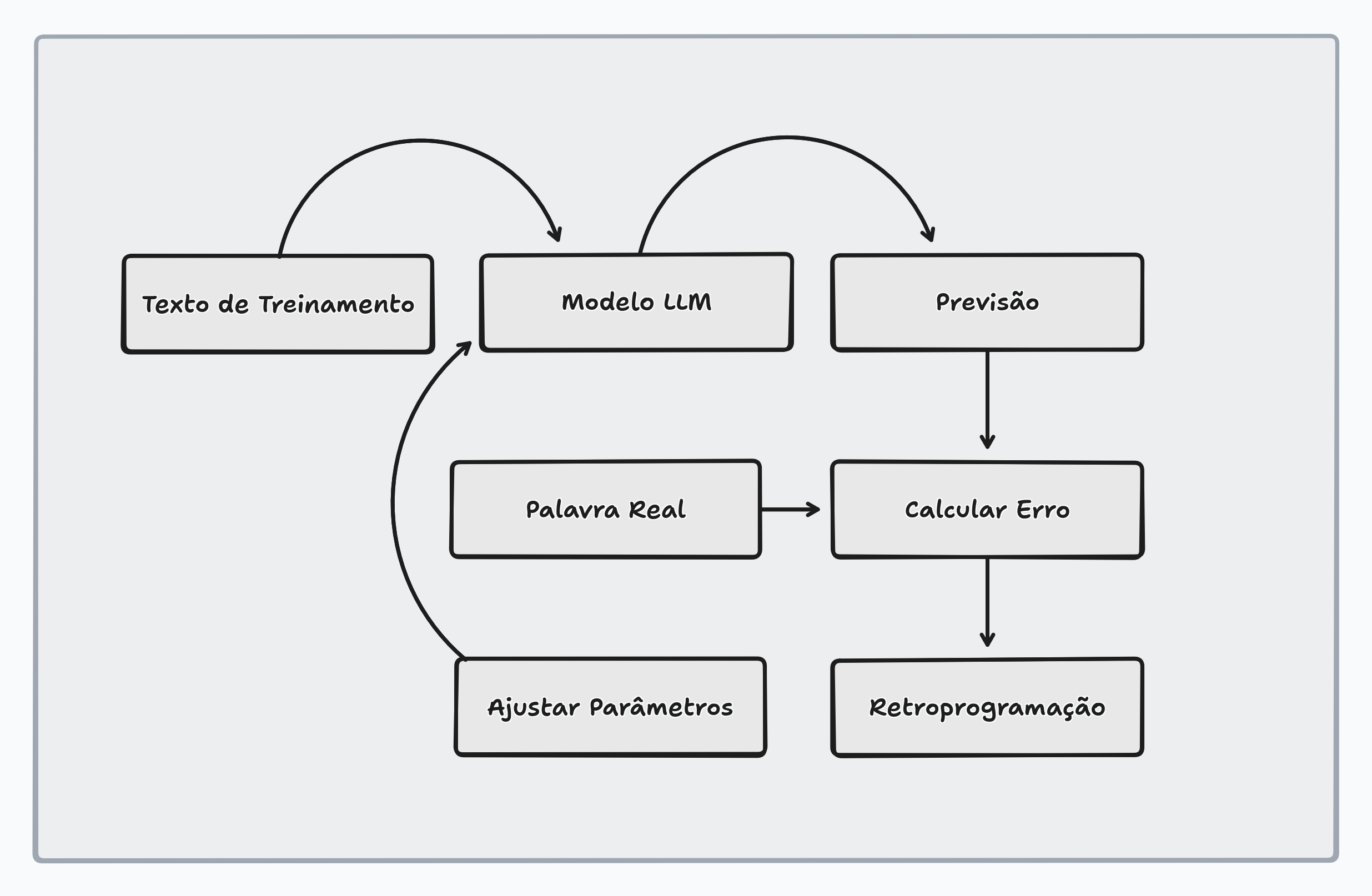
Repita isso trilhões de vezes e o modelo começa a produzir previsões bem precisas, inclusive em textos que nunca viu.
Pré-treinamento vs. fine-tuning: duas etapas distintas
O processo descrito acima é o pré-treinamento. Ele ensina o modelo a ser um excelente completador de texto, mas há um problema: completar texto da internet não é o mesmo que ser um assistente útil.
Um modelo pré-treinado pode continuar qualquer texto, mas não necessariamente vai responder perguntas de forma útil ou evitar conteúdo problemático.
RLHF: aprendizado por reforço com feedback humano
Para transformar um completador de texto em um assistente, os desenvolvedores aplicam uma segunda fase de treinamento chamada RLHF (Reinforcement Learning from Human Feedback):
- Humanos avaliam diferentes respostas do modelo para a mesma pergunta
- Essas avaliações ensinam o modelo quais tipos de resposta são preferíveis
- O modelo é ajustado para produzir mais respostas do tipo “preferível”
Esse processo alinha o modelo com as expectativas humanas de utilidade, segurança e precisão.
A arquitetura Transformer: o coração dos LLMs modernos
Antes de 2017, modelos de linguagem processavam texto sequencialmente, uma palavra por vez. Isso era lento e dificultava capturar dependências de longo alcance.
O paper “Attention Is All You Need” (Vaswani et al., 2017) introduziu a arquitetura Transformer, que revolucionou o campo.
Embeddings: traduzindo palavras em números
O primeiro passo em qualquer modelo de linguagem é converter texto em números. Cada palavra (ou token) é representada por um vetor, uma lista de centenas ou milhares de números.
Esses vetores são chamados embeddings e codificam o “significado” das palavras de forma que palavras similares tenham vetores similares.
O mecanismo de atenção
O grande diferencial dos Transformers é o mecanismo de atenção (attention). Em vez de processar palavras uma por vez, o modelo analisa todas as palavras simultaneamente e permite que cada palavra “consulte” todas as outras para refinar seu significado.
Por exemplo, na frase “O banco estava vazio”, a palavra “banco” precisa saber se estamos falando de uma instituição financeira ou um assento. O mecanismo de atenção permite que “banco” consulte “vazio” e outras palavras do contexto para resolver essa ambiguidade.
Matematicamente, a atenção calcula:
1
Attention(Q, K, V) = softmax(QK^T / √d_k) V
Onde Q (Query), K (Key) e V (Value) são projeções aprendidas dos embeddings de entrada.
Camadas e profundidade
Um Transformer típico empilha múltiplas camadas, cada uma contendo:
- Multi-Head Attention: Múltiplos mecanismos de atenção em paralelo
- Feed-Forward Network: Uma rede neural densa que processa cada posição independentemente
- Normalização e Conexões Residuais: Técnicas para estabilizar o treinamento
O GPT-4, por exemplo, possui estimadas 120 dessas camadas empilhadas, enquanto o Llama 3.1 405B tem 126 camadas.
Visualizando a arquitetura
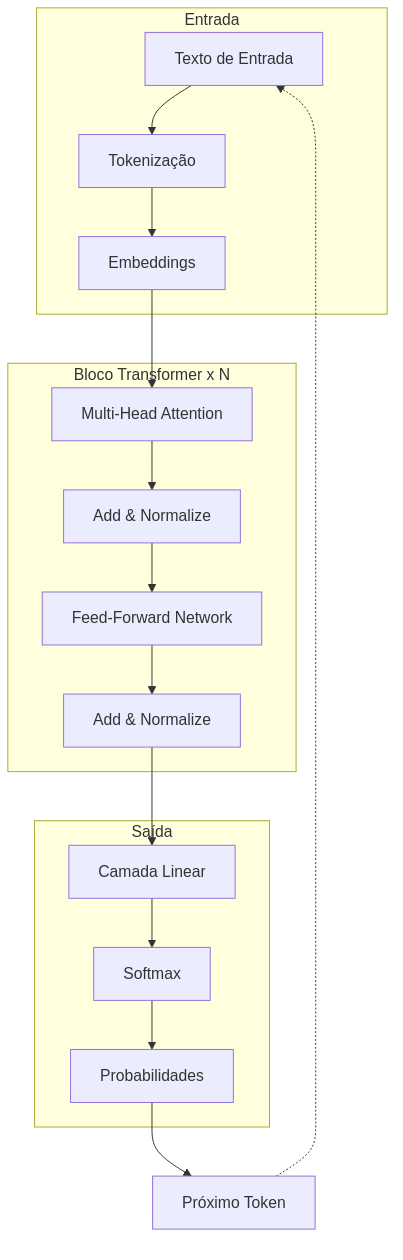
O diagrama acima ilustra o fluxo de dados através de um Transformer. O texto entra, é convertido em embeddings, passa por múltiplas camadas de atenção e redes feed-forward, e finalmente produz uma distribuição de probabilidades sobre o vocabulário.
A escala computacional: números que impressionam
Treinar um LLM moderno requer poder computacional absurdo. Para ilustrar:
Se você pudesse realizar um bilhão de operações matemáticas por segundo, quanto tempo levaria para executar todas as operações necessárias para treinar um dos maiores modelos de linguagem?
A resposta: mais de 100 milhões de anos.
Isso só é possível graças a:
- GPUs: Chips especializados em processamento paralelo
- Clusters: Milhares de GPUs trabalhando em conjunto
- Paralelização: A arquitetura Transformer permite que grande parte do processamento ocorra simultaneamente
O custo de treinar um modelo de ponta pode facilmente ultrapassar dezenas de milhões de dólares apenas em computação.
Testando na prática com Python
Podemos explorar alguns desses conceitos com código. Aqui está um exemplo usando o Gemini do Google no Google Colab:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
# Instalar/atualizar a biblioteca (Google Colab)
!pip install -q -U google-generativeai
import google.generativeai as genai
from google.colab import userdata
# Configurar API key usando secret do Colab
genai.configure(api_key=userdata.get('GEMINI_API_KEY'))
# Usar modelo Gemini
model = genai.GenerativeModel('gemini-2.0-flash')
def ver_probabilidades(texto: str):
"""Mostra possíveis continuações usando Gemini."""
prompt = f"""Você é um especialista em modelos de linguagem. Dado o início da frase "{texto}", liste as 5 palavras mais prováveis que um modelo de linguagem escolheria como próxima palavra.
Responda APENAS neste formato exato, com porcentagens estimadas:
palavra1 - XX%
palavra2 - XX%
palavra3 - XX%
palavra4 - XX%
palavra5 - XX%
"""
response = model.generate_content(prompt)
print(f"Texto: '{texto}'")
print(f"\nPróximas palavras mais prováveis:")
print("-" * 40)
print(response.text)
# Exemplo de uso
ver_probabilidades("O céu está")
Configuração: No Google Colab, adicione sua API key do Gemini como um secret chamado
GEMINI_API_KEY. Você pode gerar sua key em aistudio.google.com/app/apikey.
Output esperado:
1
2
3
4
5
6
7
8
9
Texto: 'O céu está'
Próximas palavras mais prováveis:
----------------------------------------
azul - 35%
claro - 22%
nublado - 18%
lindo - 12%
escuro - 8%
Este código demonstra exatamente o que discutimos: o modelo analisa o contexto e estima quais palavras têm maior probabilidade de continuar a frase.
Conectando com outros projetos
Se você quer rodar modelos localmente, veja meu post sobre InstructLab e Skupper, onde exploro como criar chatbots com dados protegidos usando conexões seguras entre diferentes ambientes.
Conclusão
No fundo, LLMs são completadores de texto que aprenderam padrões a partir de volumes enormes de dados. Um objetivo simples (prever a próxima palavra), escala absurda (bilhões de parâmetros, trilhões de tokens), uma arquitetura eficiente (Transformer com atenção) e uma fase de alinhamento (RLHF). Junto, isso produz sistemas que parecem “entender” linguagem, embora estejam executando operações matemáticas em larga escala.
Entender esses fundamentos ajuda a usar melhor as ferramentas, identificar limitações (alucinações, vieses) e avaliar com mais realismo o que elas de fato fazem.
LLMs são ferramentas úteis. Não são mágica, não são inteligência geral. São matemática numa escala que é difícil de visualizar.
Referências
- Vaswani, A. et al. (2017). Attention Is All You Need. NeurIPS.
- Brown, T. et al. (2020). Language Models are Few-Shot Learners. NeurIPS.
- Ouyang, L. et al. (2022). Training language models to follow instructions with human feedback. NeurIPS.
- Radford, A. et al. (2019). Language Models are Unsupervised Multitask Learners. OpenAI.
- 3Blue1Brown. (2024). How LLMs Work. YouTube.